The exponential growth in large language model (LLM) sizes has significantly outpaced improvements in hardware memory. As recent releases like Meta's Llama 4 Scout (109B parameters) and Llama 4 Maverick (400B parameters) show, deploying these massive models on limited hardware, even datacenter-class 80GB GPUs, requires substantial memory and compute optimizations.
Model compression has emerged as a critical solution to bridge this hardware-software gap. It enables cost-effective, low-latency deployments while maintaining high model quality.
Why optimize models?
There is a growing disparity between model sizes and available GPU memory. Some of today’s largest MoE architectures now exceed 1.8 trillion parameters. In contrast, even advanced GPUs like Blackwell are limited to 192GB of memory.
Quantization addresses this gap, significantly reducing the memory required to store and run models. For instance, compressing a 109B model from 220GB in BF16 to 55GB using INT4 (Table 1) allows for single-GPU deployment and lowers compute costs.
Optimization | Params size (GB) | GPUs |
BFloat16 | 109 * 2 ~= 220GB | 3 x 80GB |
INT8/FP8 | 109 * 1 ~= 109GB | 2 x 80GB |
INT4 | 109 * 0.5 ~= 55GB | 1 x 80GB |
Similarly, quantizing the 400B-parameter Llama Maverick model from 800GB in BF16 to 200GB (Table 2) using INT4 reduces GPU requirements from a 10-GPU multi-node setup to just 3 GPUs.
Optimization | Params size (GB) | GPUs |
BFloat16 | 400 * 2 ~= 800GB | 10 x 80GB ← requires multi-node! |
INT8/FP8 | 400 * 1 ~= 400GB | 5 x 80GB |
INT4 | 400 * 0.5 ~= 200GB | 3 x 80GB |
Optimization provides several advantages. It reduces memory usage, freeing up GPU RAM for critical components like the KV Cache. It accelerates inference by leveraging low-precision tensor cores available in modern GPUs. And most importantly, as shown in Figure 1, it achieves minimal or no degradation in model accuracy. In fact, in some cases, the regularization effects of quantization can even improve performance.

Step 1: Answer 2 important questions
When considering model optimization, 2 fundamental questions must be addressed: the inference use case and the available hardware.
First, determine whether the model will be used in an online or offline inference scenario. Online inference typically involves interactive applications like chatbots, where minimizing latency is key. In such cases, input sizes are often small, meaning the GPU is not fully saturated. The bottleneck shifts from computation to data movement, making weight-only quantization schemes (such as W8A16 or W4A16) highly effective.
Offline inference refers to batch processing or high-throughput use cases like summarization or document classification. Here, the GPU is kept consistently busy, and computation becomes the dominant cost. Thus, quantization formats that accelerate the rate of computation, such as FP8 or INT8 applied to both weights and activations (such as W8A8), are preferred.
The second question concerns the hardware. Older GPUs (e.g., A100, A40, T4) are better suited to INT8 due to their optimized tensor cores. In contrast, modern architectures like Hopper and Blackwell have native support for FP8 operations, making FP8 quantization a compelling choice.
Step 2: Select a suitable quantization scheme
Once the use case and hardware have been defined, the next step is selecting the quantization scheme. For online inference with fewer requests per second, weight-only quantization is recommended. It significantly reduces the memory footprint and the data transfer load on the GPU, which translates to faster response times.
In contrast, for offline inference where large batches and many simultaneous queries are expected, both weights and activations should be quantized. INT8 or FP8 formats maximize GPU throughput by fully utilizing the low-precision tensor cores available in the hardware.
LLM Compressor supports multiple quantization schemes:
- W4A16 for memory-bound, low-QPS scenarios.
- INT8 and FP8 for compute-bound, high-throughput deployments.
- KV Cache Quantization for efficient long-context inference.
- Structured sparsity (e.g., 2:4) for compact, efficient model representation.
These strategies allow LLM Compressor to adapt to different deployment constraints while maintaining high accuracy.
Choosing the right quantization scheme
LLM Compressor supports a wide range of optimization strategies that address different deployment needs. Weight-only schemes like W4A16 are well suited for memory-constrained, low-QPS scenarios. Full quantization using INT8 or FP8 is ideal for high-throughput, compute-intensive deployments. For reducing model size further, 2:4 structured sparsity can be applied. In long-context workloads, quantizing the KV Cache offers additional memory savings.
As Figure 2 illustrates, LLM Compressor sits in the model lifecycle between training and deployment. It takes a Hugging Face-compatible model and applies compression algorithms defined in a modular "recipe." These recipes specify techniques such as round-to-nearest, SmoothQuant, GPTQ, or various sparsity modifiers. For a visual overview of many of these quantization techniques, see this guide.

Quantization workflow using LLM Compressor
The quantization process begins by loading a model using the standard Transformers interface, such as AutoModelForCausalLM. Next, a compression recipe is defined. This specifies which quantization or sparsity algorithms to apply. Once the model and recipe are ready, the oneshot() function executes the compression process. The model is then saved in the compressed tensors format, ready for deployment.
from transformers import AutoModelForCausalLM
# Select model and load it.
MODEL_ID = "meta-llama/Meta-Llama-3-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, device_map="auto")While there are some weight-only quantization recipes which do not require a calibration dataset, most quantization and compression recipes require calibration data to calibrate weight adjustments and activations.
For simple weight-only quantization, a calibration dataset is typically not needed. However, activation quantization and advanced techniques such as GPTQ, SparseGPT, and SmoothQuant require representative datasets to calculate parameter sensitivities, activation ranges, and scaling factors. GPTQ is our default weight-only quantization technique, so we will use it for the following INT4 W4A16 example.
from llmcompressor.modifiers.quantization import QuantizationModifier
# Select recipe
recipe = QuantizationModifier(
targets="Linear",
scheme="W4A16"
ignore=["lm_head"])For calibration data, you can use existing datasets hosted on Hugging Face or your own custom datasets.
from llmcompressor.transformers import oneshot
# Apply algorithms.
oneshot(
model=model,
recipe=recipe,
dataset="ultrachat_200k",
splits={"calibration": "train_sft[:512]"},
output_dir="compressed_path")Efficient deployment with vLLM
Once compressed, the model is stored using highly efficient formats. INT4 weights are packed into INT32 containers, while sparsity is encoded using bitmasks. These formats are natively supported by vLLM, allowing users to load and deploy models seamlessly.
vLLM automatically identifies which layers have been quantized or compressed and selects the appropriate kernels for inference. This automation streamlines deployment and maximizes inference performance without additional user configuration.
Composing compression strategies
LLM Compressor’s architecture supports algorithm composition, enabling users to apply multiple optimization techniques in sequence. For example, you can apply SmoothQuant to balance scale ranges before quantizing with GPTQ. This flexibility empowers researchers and practitioners to experiment with novel combinations that push the limits of performance and efficiency.
recipe = [
SmoothQuantModifier(
smoothing_strength=0.8),
QuantizationModifier(
targets="Linear",
scheme="FP8",
ignore=["lm_head"])]recipe = [
SparseGPTModifier (
sparsity=0.5,
mask_structure="2:4"),
QuantizationModifier(
targets=["Linear"],
scheme="FP8",
ignore=["lm_head"]),
]Expanding the ecosystem
Beyond its core functionality, LLM Compressor integrates broadly with other tools and platforms. It supports inference within the Hugging Face Transformers ecosystem, enabling accuracy validation pre-deployment. It also interfaces with fine-tuning frameworks such as Axolotl, allowing users to maintain sparsity during supervised training.
Public support from the Meta AI team during the Llama 4 launch, where LLM Compressor was used to release FP8 versions of their models, demonstrates its real-world impact. All released models include evaluation reports to verify performance and recovery.
Calibrating and compressing large models on a single GPU
Compression of ultra-large models like DeepSeek’s 685B-parameter MoE, which requires 1.2TB of memory in BF16, can be done on a single GPU using layer-sequential calibration. This technique loads and calibrates one model layer at a time, offloading outputs before moving on (see Figure 3). This dramatically reduces memory requirements without sacrificing calibration quality.

Layer-sequential calibration in practice
Using tools from Hugging Face and the Accelerate library, LLM Compressor segments the model into layers. These can be further divided into sub-components like self-attention and feed-forward networks. Each layer is loaded, calibrated, and compressed in turn, minimizing memory usage and ensuring accurate quantization. This technique is particularly beneficial for resource-constrained users or environments.
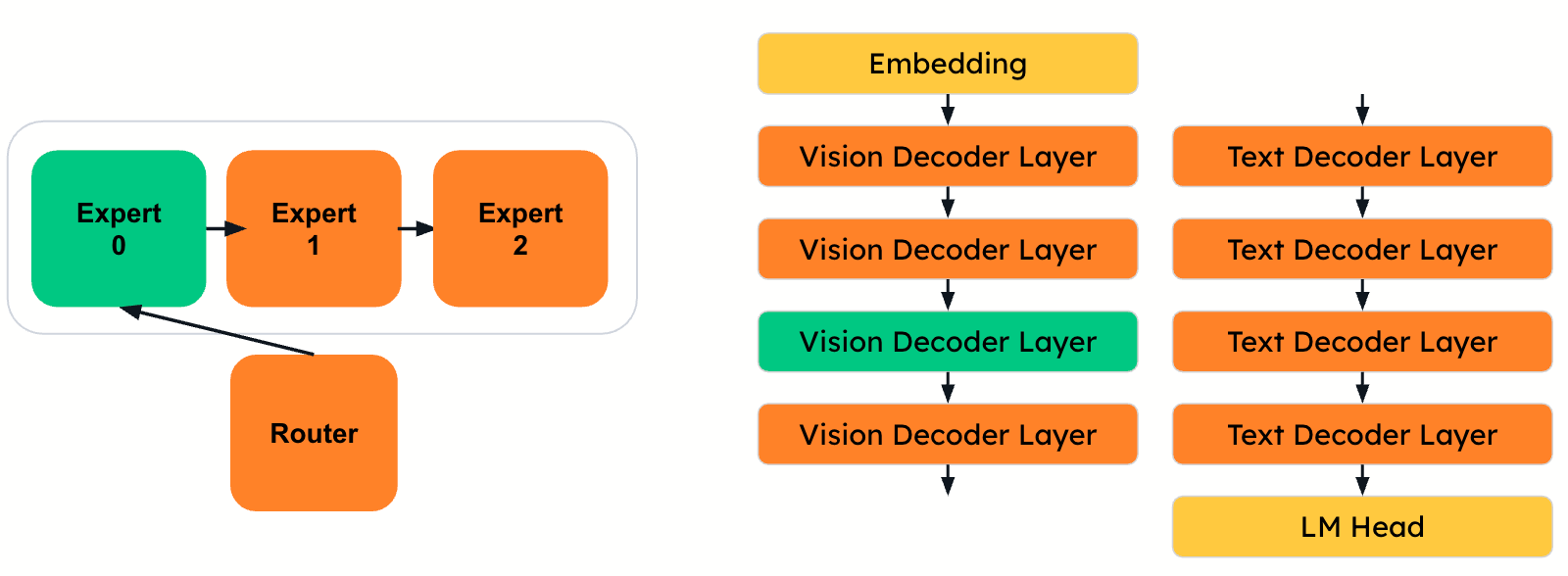
Generalizing to multimodal and MoE architectures
This per-layer approach generalizes to vision-language models and mixture-of-expert (MoE) architectures. In multimodal models, vision-specific decoder layers are processed similarly to text layers. In MoE models, individual expert layers—often too large to process as a whole group—can be calibrated and compressed independently (see Figure 4). DeepSeek’s models, for example, include up to 256 experts per MoE layer, making granular compression essential.
The results are research-backed and validated across multiple benchmarks, demonstrating high compression ratios with minimal accuracy loss.
Text models:
Llama 3 Herds
MiniCPM
Vision-language models:
Mllama (Llama 3.2)
Phi3 Vision
Pixtral
Qwen2.5 VL
Llava
Audio and multimodal models:
Whisper v3
Mixtral
DeepSeek v2.5
Support in progress:
DeepSeek v3
Llama 4 Scout
Conclusion
Model optimization is no longer optional—it's essential for efficient, scalable LLM deployment. LLM Compressor bridges the gap between fine-tuning and production with robust support for quantization, sparsity, calibration, and seamless integration with vLLM. Whether you're optimizing for cost, latency, or innovation, LLM Compressor is the foundation for next-generation AI inference.
To get started, explore our Hugging Face collection, contribute to the GitHub repo, and join the community of developers and researchers advancing efficient AI.
